
What is data modeling and what is its purpose?
Data modeling is a way to visualize a data storage system. The system is represented by a diagram that attempts to explain the data to be stored, the relationships between the different types of data, and the formats, attributes, and rules that make the system work. The data model can be created before a system is built, or used to understand an existing system.
Because data modeling uses a standardized approach to representing systems, it can readily be shared with other teams and any stakeholders. This makes data models ideal for explaining the design of a system across all levels of a company. The stakeholders can give feedback before anything gets built and make sure that the business requirements are being met.
Make your own ER diagram in Gleek.
Data models are an important type of documentation, as they preserve the original design, or blueprints for the system, and can be easily updated and shared again as requirements change. They allow developers to spot problems with data quality and reduce errors before they become a costly problem. They also encourage efficiency, by forcing the designer to think about how to organize and optimize the database.
Data models: the types
Conceptual
This is the first level of data modeling and is focused on the overall structure of the system. Conceptual models, or domain models, can start out simple, be passed on to stakeholders for feedback, and then be fleshed out as the requirements are better understood. They will attempt to represent the entities involved in the system and the relationships between those entities, while paying less attention to their attributes.
Logical
After conceptual modeling comes the more detailed process of defining all the attributes of the entities to be represented. The relationships are also more fully mapped out, so that the model shows how each entity is related. Logical models do not even attempt to deal with technical specifications or requirements.
Physical
Now we come to the final design of the schema, where attention is paid to the primary, secondary, or foreign keys, including surrogate keys if used, any restraints, and the tables and columns that will constitute the actual database. At this stage, the model can also concern itself with database management issues. Data normalization will also be carried out at this stage, in order to optimize the database now that all the elements required are fully understood.
Data modeling: the process
There are a number of great tools on the internet that can be used for data modeling, so how you design your database is a matter of personal choice (personally we like Gleek 😊). The workflow for data modeling will depend on what stage the developer is at, but it will usually go something like this.
Entities
The real-world elements in the system are defined first. Entities can be concepts, events, objects, persons, companies, or systems. If a thing can be identified as discrete, then it can be an entity.
Attributes
The characteristics that differentiate the entity from other entities are its attributes. These can be anything that defines the entity, such as name, category, ID, date of creation, or description. The types of attributes will depend on the type of system being created.
Relationships
Each entity in a database has some sort of relationship with the other entities. They may be related because they interact with each other, or they may be dependent on each other, or have a parent-child relationship, with inheritance of attributes. Whatever the relationship, it needs to be explained and represented during the process of data modeling.
Normalization
Database normalization is based on removing ambiguities from relationships and removing repetition or redundancy. This is carried out by reviewing the various primary, secondary, or foreign keys associated with each entity.
Read more on the topic in Primary keys vs. foreign keys: The key differences article.
Validation
This phase is hopefully when it all comes together, with the rules, formats, requirements, and syntax being checked, along with the entities, relationships and keys. If changes are needed, the designer goes over the model again to refine it.
Data modeling: the types
Databases have been around for a long time, with the earliest computerized databases being introduced in the early 1960s. So it stands to reason that data modeling has gone through a number of different iterations as business needs have changed. Here are some of the different types of data models that have been developed.
Hierarchical data models
This simple tree-like structure is based on each record having a single root or parent that links to one or more child tables. Each record has a collection of fields and each field has a single value. It is still widely used, as it can be very quick to access data at the top of the hierarchy.
Relational data models
This popular database model uses single or multiple tables, or relations, to represent the data, with each row, or tuple, of the table storing information on a single entity. In a relational database, a record can apply to any number of tables, so it avoids replication.
Entity-relationship (ER) data models
ER data models use diagrams to map the relationships between entities in a database. An ER diagram enables everyone involved in the design of the database to see a graphical representation of the requirements for the database. An online tool like Gleek makes it easy to create ER diagrams without even using your mouse thanks to its unique syntax. It’s perfect for rapidly sketching out ideas for cross-team collaboration.
Make your own ER diagram in Gleek.
Object-oriented data models
Object-oriented data models are based on the idea of an object representing an abstraction of a real-world entity. These objects can be grouped according to class. These models emphasize the reuse of methods and inheritance, thereby increasing efficiency.
Dimensional data models
Designed to optimize data retrieval in data warehouses, dimensional data models actually increase redundancy so that information can be accessed as rapidly as possible. Two types of dimensional data models are star schema and snowflake schema.
What is an example of data modeling?
Data models essentially describe entities and relationships, so let’s use an example of an ER model. In this example, you can see that we’re representing the relationship between a store, its customers, products, sales, and merchants.
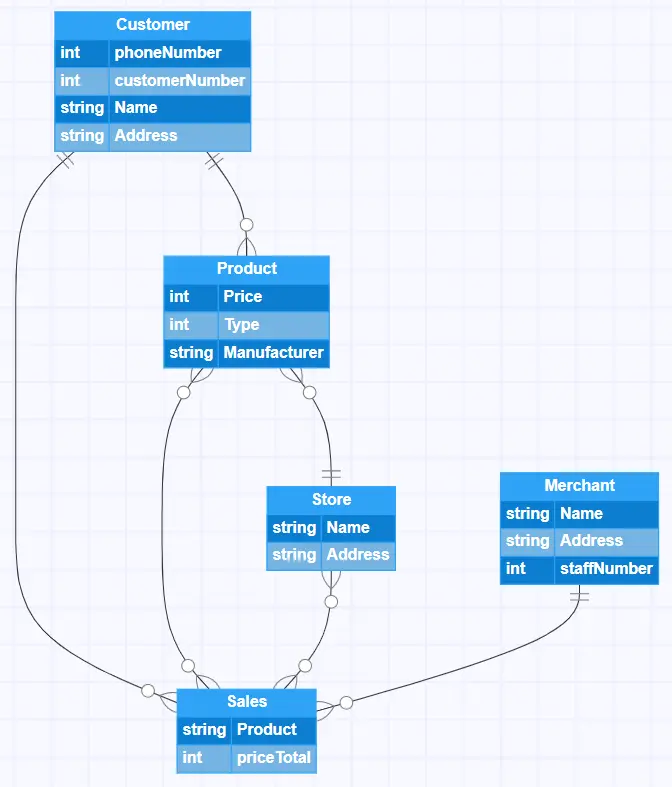
Each entity has attributes (either a string or an integer) and also has a relationship to other entities that is represented using Crow’s Foot notation. If you want to understand more about how ER diagrams are used to model databases, you might like to check out this more detailed explanation. Or you can even dive straight in and experiment with the above example, as it’s one of the many templates provided in the Gleek diagramming tool!
Related posts
Primary keys vs. unique keys: Fundamental differences
Improving your database skills with many-to-many relationship examples
The logical data model explained
Exploring One-to-Many Relationship Examples in Databases
What is the entity-relationship diagram in database design?
Quick guide to physical data modeling
4 Key principles of effective database design
Derived Attributes in ER diagrams: A comprehensive exploration
10 best data modeling tools: free & open source
How do you convert an ER diagram into a relational schema?