
In relational database tables, we use ‘keys’ to identify and find information more easily, or to show the relationships between the data of two different tables. Two of these identifiers are primary keys, and unique keys. Let’s take a closer look.
Make your own ER diagram in Gleek.
What is a primary key?
Primary keys are a column or set of columns in a relational database table that uniquely identify items in the rows of the table. Each primary key entry identifies one, and only one, item. Let’s say we have a table with people in a database. They each have a name, and an ID number. While two people may have the same name, no two can have the same ID number. In this example, the ID number is the primary key.
Read also Primary key vs Foreign key comparison.
Moreover, in database design, a surrogate key—a unique identifier generated artificially—may complement or replace natural primary keys to enhance data integrity and optimize database performance.
Find out What the main database design principles are.
What is a unique key?
Unique keys are columns in a relational database table that uniquely identify items in the rows. This sounds a lot like a primary key, but the main difference is that unique keys can have NULL values. Their purpose is to prevent duplicate items in rows, but the items in the row also don’t need to have a value.
Going back to our ID example, let’s say that there is a group of people at the post office, and each of them has a ticket that tells them when they can go to the window. Maybe someone is at the post office with their friend, and they don’t have a ticket. Their ID number is still the primary key, and the ticket number is a unique key, because it is possible for someone not to have a ticket, and no two tickets have the same number.
When primary keys are used
Primary keys are used in ‘parent’ tables, which other tables can be linked back to. They are used for identifying every item in a table that does not have a NULL value, and for creating a clustered index. It is important to note that relational tables cannot function without a primary key, because it becomes nearly impossible to find information in the table. Changing the data of primary keys should also be done with care, as it can cause major issues in the table.
When unique keys are used
Unique keys are used to prevent any duplicate values in a table, but when the value can also be NULL. There can be more than one unique key, and they can easily be changed or removed, unlike a primary key. Unique keys, by nature, create non-clustered indexes, and do not support increment values.
The main differences between primary and unique keys
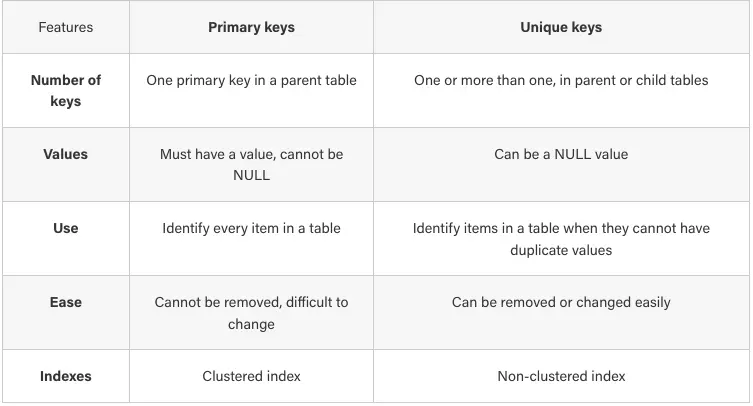
Though quite similar on the surface, the functions of primary and unique keys differ, making them both a vital part of relational database tables. Primary keys are usually incremental in value, and create clustered indexes, while unique keys are the opposite. There can be one or many unique keys, while there can only be one primary key. Both types of key can exist within the same table. Unique keys are used when we want to identify specific items, and do not want any duplicate values. Primary keys are also used to uniquely identify items, but every row must have a primary key, while it is possible for the row to be lacking a unique key.
Make your own ER diagram in Gleek.
Looking for a new diagramming tool? Try Gleek – a text-based tool you can use to create ER and UML diagrams with just a few keystrokes. Get started for free here.
Related posts
Primary keys vs. foreign keys: The key differences
The logical data model explained
What is the entity-relationship diagram in database design?
Quick guide to physical data modeling
Surrogate Keys: How are they represented in ER diagrams?
10 best data modeling tools: free & open source
How do you convert an ER diagram into a relational schema?